Les cours d' info

La Corse

L' ASSE

Humour


Le modčle de référence OSI

Le modčle de référence OSI (Open Systems Interconnect) traite des connexions entre systčmes ouverts ŕ la communication avec d’autres systčmes.
Il est composé de 7 couches réseaux répondant toutes aux principes suivant :
1-Une doit ętre créer lorsqu’un nouveau niveau d’abstraction est nécessaire
2- Chacune exerce des fonctions bien définies.
3- Les fonctions de chaque couches doivent ętre choisies en visant la définition de protocoles normalisés internationaux.
4- Le choix des frontičres entre couches doit minimiser le flux information aux interfaces.
5- Le nombre de couches ne doit ętre ni trop petit pour éviter la cohabitation dans une couche de fonction trčs différente et ni trop grand pour éviter que l’architecture ne devienne difficile ŕ maîtriser.
I-LES COUCHES RESEAUX :
A-La Couche Physique.
La couche physique ŕ pour fonction de gérer la transmission brute des bits de données sur un canal de communication. Elle s’assure qu’un bit n de valeur 1 sera toujours égal ŕ 1 ŕ son arrivée.
Un certains nombres de questions doivent intervenir lors de la mise en place de cette couche :
- Le Voltage requis pour qu’un bit prenne pour valeur 0 ou 1.
- Le délai de transmission d’un bit en Milliseconde (ms).
- Possibilité de transmission bidirectionnelle.
- Le nombre de broches des connecteurs réseaux et leurs rôles.
Les problčmes de conceptions peuvent ętre d’ordre mécanique, électrique, fonctionnel ou encore une défaillance du support physique (se trouvant sous la couche physique).
B-La Couche Liaison de Donnée.
La couche Liaison de Donnée a pour fonction la transformation de bits bruts venant de la couche Physique en liaisons exemptent d’erreurs avec la couche Réseau.
Elle a également pour but de fractionner les données de l’émetteur en Trames qui seront émise les unes aprčs les autres et reconnues par des bits spéciaux permettant de les remettre dans l’ordre, ce sont les bits de reconnaissances. Le récepteur envoie automatiquement un accusé de réception pour chaque trames reçues, ce sont les trames d’acquittements.
Cela peut engendrer des problčmes comme :
- Il est possible que, suite ŕ des perturbations d’ordre électromagnétique sur la ligne, une trame soit détruite. La couche liaison de données devra alors ré-émettre cette trame tant que la trame d’acquittement n’est pas reçue.
- Si la trame d’acquittement est détruite lors de sa transmission, il peut y avoir des doublons de trames. C’est ŕ cette couche de régler les problčmes de doublons.
De plus, elle permet de réguler le trafic du réseau grâce ŕ un mécanisme de régulation par observation des mémoires tampons. C’est ŕ dire qu’il empęche un émetteur ŕ haut débits de saturer un récepteur plus lent.
C-La Couche Réseau.
La couche Réseau permet de gérer le Sous-Réseau et vérifie son état pour éviter les encombrements. Il a également pour but de gérer tous les problčmes d’incompatibilités relatifs au transit des paquets de données dans des réseaux hétérogčnes.
Cette couche dépend de la maničre dont sont acheminées les paquets de données :
- Fondés sur des tables statiques.
- Déterminés ŕ chaque connexion.
- Dynamique avec recalcule du trajet entre émetteur et récepteur pour chaque paquets
émis afin de prendre en compte l’encombrement du réseau.
Attention : Cette couche est trčs mince, voir inexistante, dans les cas de réseaux ŕ diffusion car les routages sont trčs simples.
d-La Couche Transport.
Cette couche va chercher des données dans la couche Session, puis elle les coupe en entités plus petites pour enfin les transmettre ŕ la couche Réseau et de s’assurer qu’elles ont bien été transmises.
Elle détermine le type de service ŕ fournir ŕ la couche session. Le plus courant est le canal point ŕ point délivrant des paquets et des octets dans l’ordre d’émission. Le service est déterminé ŕ la connexion sur le réseau.
Enfin, comme pour d’autres couches, elle réalise un contrôle de flux pour empęcher la saturation d’un hôte lent par un autre plus rapide. Cependant le contrôle de flux entre hôtes est différent de celle entre routeurs.
E-La couche Session.
La couche session permet ŕ des utilisateurs travaillant sur des machines différentes d’établir des sessions entre eux, ceci leurs permettant ainsi le transport de données. Elle offre également l’accčs ŕ des services évolués utiles ŕ certaines applications comme le transfert de fichiers entre 2 postes.
Elle permet également le "contrôle du Jeton". Ceci consiste dans le fait que cette couche fournit un "jeton" que les interlocuteurs s'échangent et qui donne le droit d'effectuer une opération.
Enfin, cette couche gčre la "Synchronisation". C'est ŕ dire qu'elle insčre des points de reprise dans le transfert des données de maničre ŕ ce qu'en cas de panne, l'utilisateur ne reprenne le transfert qu'au niveau du dernier point de repčre.
F-La couche Présentation.
Elle accomplit les taches courantes et répétitives pour délester l'utilisateur. Contrairement aux autres couches, celle-ci ne s'intéresse pas au transfert fiable de bits d'un point A ŕ un point B. En revanche, elle s'intéresse de prčs ŕ la sémantique et ŕ la syntaxe de l'information transmise.
Ex : Encodage de données brutes en un standard répondant ŕ une norme lisible sur toutes les machines.
G-La couche Application.
Cette couche comporte de nombreux protocoles gérant les incompatibilités logicielles. On peut résoudre les problčmes en définissant des terminaux de réseau virtuel permettant ainsi de lire des fichiers provenant d'autres plates-formes informatiques (Apple, Sun, HP…).Ce genre de logiciel prend place uniquement dans cette couche.
De plus, cette couche a également pour but de gérer les incompatibilités dut aux différents formats de fichiers pour le transfert de fichiers, de męme que la gestion de messagerie électronique, exécution de travaux ŕ distance, la consultation des annuaires …
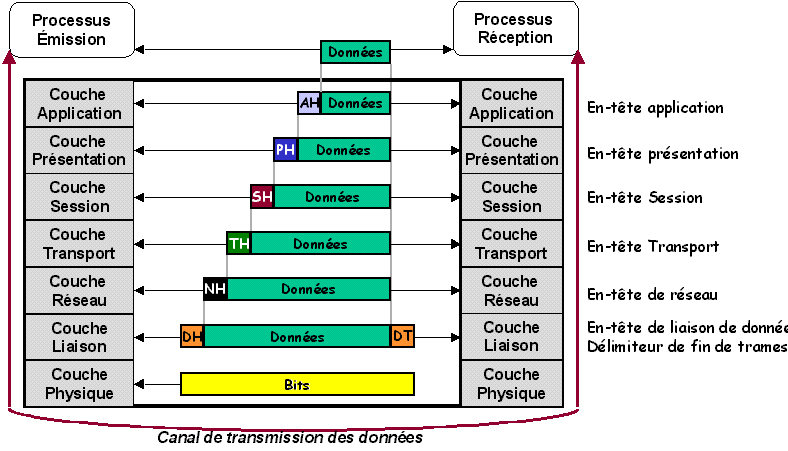
H-Transfert de données dans le monde OSI.
Lors de l'envoie de données par un processus émetteur, il les remet ŕ la couche application qui lui applique un "En-tęte d'application" (AH) puis transmet l'objet ainsi obtenu ŕ la couche Présentation et ainsi de suite jusqu'ŕ ce que les données soit réceptionné par la couche Physique. Les couches inférieures n'ont pas ŕ connaître l'existence de ces en-tętes, elles les prennent pour des données utilisateurs.
Lors de la réception d'un processus par un Hôte B, les données remontent le modčle couche par couche pour y ętre épuré des en-tętes jusqu'ŕ ne donner que les bits émis au départ du processus.
Les protocoles TCP/IP |
I-INTRODUCTION.
Il s'agit du modčle de référence du réseau ARPANET, descendant direct du réseau des réseaux : INTERNET.
ARPANET etait un réseau lancé ŕ l'initiative du Département de la Défense Américain ( le "DoD" : Departement of Defence). Il fut destiné ŕ la recherche et reliait, par le biais des lignes téléphoniques, une centaine d'universités et d'administrations.
L'arrivée des réseaux ŕ liaisons radios et satellites imposa au DoD de lancer la recherche d'une nouvelle architecture pour le réseau, celle-ci devant fournir un maximum de transparence. Elle finit par ętre connue et reconnue comme étant le modčle de référence TCP/IP, du nom de ses deux principaux protocoles.
La recherche fut axées sur un point précis : Le réseau ne doit pas ętre mis hors d'usage ŕ cause d'une panne au niveau physique (routeurs, hubs, commutateurs, cartes réseaux …), il doit également ętre impératif que les connexions soient indépendantes de l'état du sous-réseau.
Ce modčle comporte 5 couches réseaux quasiment identiques au modčle OSI. Les couches OSI 5 et 6 n'ont pas été transposées car la nécessité n'etait pas assez importante.
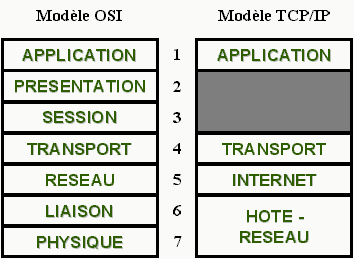
Figure 1 – Comparaison des couches OSI et TCP/IP.
A. La couche Hôte-Réseau.
Cette couche est mystérieuse et son fonctionnement n'est pas explicité. Le seul détail donné est qu'un hôte doit se connecter au réseau en utilisant un protocole permettant d'émettre des paquets IP.
Néanmoins, ce protocole n'est pas imposé et varie d'un réseau ŕ l'autre.
B. La couche Internet.
Le nom de cette couche n'a aucun rapport avec le réseau Internationale : "Internet". Bien qu'il rentre en œuvre dans celui ci. Le terme "Internet" est utilisé, ici, en tant que "interconnexions de réseaux".
Cette couche est la clé de voűte de tout le modčle TCP/IP.
- En effet, elle permet d'injecter des paquets de données dans n'importe quels réseaux. En outre, elle contrôle l'acheminement de ces paquets indépendamment les uns des autres jusqu'au destinataire. Les paquets peuvent donc arriver dans le désordre, ils seront réordonnés par les couches supérieurs.
- Son fonctionnement ressemble ŕ celui du systčme postal. C'est ŕ dire qu'une série de lettres ŕ destination de l'étranger, chaque lettre arrivera ŕ destination mais passera certainement par des bureaux de tri différents. Néanmoins, ces trajets différents n'ont aucune influence sur l'utilisateur, pas plus que les différences entre les monnaies, tarifs postaux …
- Elle définit un format standard et un protocole de transfert des paquets de données : Le protocole IP (Internet Protocol).
Elle correspond ŕ la couche Réseaux du modčle OSI, du fait que le routage et le contrôle de décongestionnement des paquets sont primordiales.
C. La couche Transport.
Elle est équivalente ŕ son homologue du modčle OSI, c'est ŕ dire qu'elle permet ŕ deux entités de communiquer sur un réseau.
Deux protocoles régulent cette couche :
- Le protocole TCP (Transfer Control Protocol) qui permet la remise de paquets sans erreurs.
- Le protocole UDP (User Datagram Protocol) qui permet la remise de paquets sans séquence ment et sans contrôle de flux.
D. La couche Application.
Le modčle TCP/IP n'a pas de couche comparable ŕ la couche Session et Présentation car elles n'ont quasiment aucune utilité.
La couche Application héberge des protocoles de haut niveau comme par exemple :
- TELNET (Protocole de terminal virtuel).
- FTP (Files Transfert Protocol).
- SMTP (Protocole de messagerie électronique).
- DNS (Gestion de nom de machine).
- etc.…
A ces protocoles d'origines se sont greffés beaucoup d'autres lesquels le NNTP (Gestion d'articles de groupes de discussions – Newsgroups).
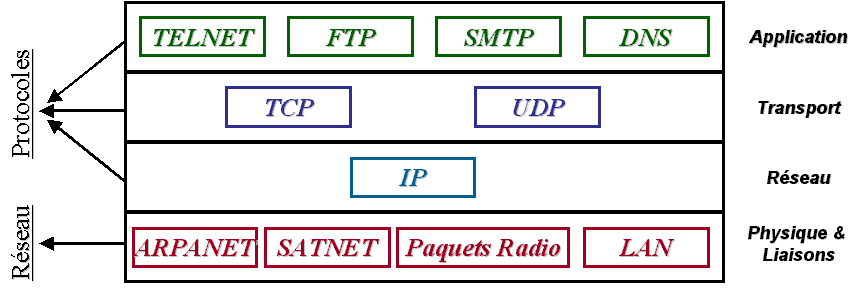
Figure 2 – schéma des couches du modčle TCP/IP.
La couche OSI n°2 :
La couche Liaisons de Données
1-Introduction.
- Offre une interface de service ŕ la couche Réseau (couche n°3).
- Détermine la façon dont les bits reçus par la couche physique sont agencés en trames.
- Traitement des erreurs de trames.
- Contrôle de flux pour réguler le volume des données échangées entre les hôtes.
2-Fonction Principale : Transmission de données de la couche Réseau d’un Hôte A ŕ celle d’un Hôte B.
La couche réseau de l’émetteur contient un processus qui délivre des bits ŕ la couche Liaison de données. Il appartient ensuite ŕ celle-ci de les transmettre au destinataire afin que sa couche réseau les traites.
Pour ętre en mesure de délivrer ce service ŕ la couche réseau, la couche Liaison de données doit utiliser les services de la couche physique afin d’effectuer le transport physique des données. Ce flux de donnée effectue un chemin imagé sur la figure 1. Néanmoins il est admis que le flux de données effectue un chemin virtuel ne citant pas la couche physique, les couches liaisons de données communiquant ainsi par l’intermédiaire d’un protocole de liaison.

Figure 1 – chemin de communication Réel et Virtuel
Les services fournies par cette couche varient selon les systčmes informatiques mais ils peuvent ętre classés parmi 3 catégories :
- fiable - Les services sans connexions et sans accusé de Réception.
- Les services sans connexions et avec accusé de Réception.
+ fiable - Les services avec connexions et avec accusé de Réception.
A. La notion de trames.
La couche liaison de données de l’émetteur reçoit des paquets de bits de sa couche réseau. Pour faciliter leurs envois, la couche liaison de données les partages en trames et en calcule une somme de contrôle d’erreur pour pouvoir detecter les erreurs de transmission (éronage de bits, de trames …).
Lorsqu’une trame est reçue, le récepteur recalcule immédiatement la somme de contrôle d’erreur. Si la somme n’est pas conforme ŕ la trames, la couche liaison du récepteur sait alors qu’il y a eut un problčme et elle prend alors les mesures en conséquences.
Les types de contrôle d’erreur sont :
- Le compteur de caractčre.
- Avec caractčre de début de trames, de fin de trames et de transparence.
- Avec utilisation de fanions de début, de fin de trames, avec des bits de transparence.
- Violer le codage normalement utilisé dans la couche physique.
B. Le contrôle d’erreur.
Généralement, les protocoles permettent ŕ l’émetteur de s’informer sur le fonctionnement du récepteur. Et ce par l’intermédiaire de trames de contrôle mais il peut y avoir des problčmes :
+
Pas de réception de trames.
- Pas d’émission de trames de contrôle de l’émetteur.
- Utilisation d’un temporisateur par le récepteur.
- réémission de la trame jusqu'ŕ réception.
+
Erreur détecté dans la tram reçu.
- Emission d’une trame de contrôle négative par le récepteur.
- réémission de cette trames.
+
Réception complčte ou partiel d’une trame.
- Emission d’une trame de contrôle.
- Pas de réception de la trame de contrôle.
- Temporisation de l’émetteur
- réémission de la trame (possibilité de doublons).
C’est ŕ la couche de liaison de résoudre les problčmes de doublons de trames.
C. Le contrôle de flux.
Il s’agit d’un mécanisme permettant de réguler le débit de bits partant d’un émetteur ŕ haut débit pour un récepteur moins rapide car męme si les bits sont envoyé sans erreur, le récepteur les perdra par un manque de rapidité de traitement.
Il se base sur un principe de rétroactions, c’est ŕ dire que l’émetteur ne peut envoyer des trames ou récepteur que si celui-ci lui en donne l’autorisation.
3-La couche liaison de données dans Internet.
Le réseau Internet nécessite un protocole de liaison permettant de délimité des trames de bits et de réaliser des contrôles d’erreur.
Il existe deux protocoles principaux de liaisons de données :
- Le protocole SLIP (Serial Line Internet Protocol)
- Le protocole PPP (Point to Point Protocol)
+ Le protocole SLIP (RFC 1055)
Il a été conçu dans le but de relier des stations Sun ŕ Internet en utilisant un modem et une ligne téléphonique. La station émettrice envoie des paquets IP bruts avec ŕ la fin de chaque paquets, un fanion (l’octet 0xCO).
Bien qu’il soit encore beaucoup utilisé, le protocole SLIP ŕ néanmoins de nombreux inconvénients :
+ Il n’effectue ni détection, ni contrôle d’erreurs, c’est aux couches supérieurs de s’en charger.
+ Il ne gučre que le protocole IP. Toute les réseaux n’ayant pas IP comme langage natif (ex :LAN Novell) ne seront pas géré.
+ Chaque hôtes dans la liaison doit connaître l’adresse de l’autre avant l’établissement de la connexion. PAS D’ADRESSAGE P DYNAMIQUE.
+ Il ne permet pas d’authentification, de sorte qu’a aucun moment on ne peut savoir avec qui on communique.
+ De nombreuses versions de SLIP ont été devellopées mais elles sont toute incompaptibles.
+ Le protocole PPP (RFC 1661-RFC 1662-RFC 1663)
Le protocole Point ŕ Point (PPP) propose une méthode standard pour le transport d'unités de transmission de la couche réseau, nommés datagrammes. Il est utilisé pour des liaisons simples transportant des paquets de données entre deux éléments. Ces liens permettent une communication simultanée bidirectionnelle (full-duplex), et sont supposés transmettre des paquets de données dans l'ordre. PPP comprend trois composants principaux:
í
Une méthode qui délimite de façon non ambiguë la fin d'une trame et le début de la suivante. Le format de la trame permet également la détection des erreurs. Cette méthode est appelée encapsulation.í
Un protocole de contrôle de liaison, appelé LCP (Link Control Protocol), qui active une ligne, la teste, négocie les options et la désactive sans erreur lorsque la transmission est terminée.í
Une façon de négocier les options de la couche réseau indépendamment du protocole de couche réseau ŕ utiliser. La méthode choisie consiste ŕ avoir un NCP (Network Control Protocol) différent pour chaque couche réseau supportée.
LA SOUS-COUCHE DE
CONTRÔLE D’ACCES AU CANAL :
La couche MAC
1-INTRODUCTION.
Cette couche est utilisée uniquement dans des réseaux ŕ diffusion : C’est la partie basse de la couche de liaison. Ces types de réseau permettant aux abonnés d’émettre et de recevoir des informations sur le réseau. Le problčme étant de savoir qui, ŕ un moment donné, a le droit d’émettre.
Ces canaux ŕ diffusion sont dit "Bidirectionnels".Ils sont également appelés :
- Canaux ŕ accčs multiples.
- Canaux ŕ accčs aléatoires.
Ils utilisent des protocoles pour déterminer le prochain élu pour émettre des bits de données. Ceux-ci sont regroupé dans une sous-couche interne de la couche de liaisons de données. Celle ci est généralement appelée :
- Sous-couche de contrôle d’accčs au canal.
- Sous-couche MAC (Medium Access Control).
Cette sous-couche est trčs importante dans les réseaux LAN. En revanche, les WAN ne sont pas concernés, hormis les réseaux satellites.
2-Les différentes techniques d’allocation de canaux de communication.
A. Les allocations statiques.
La technique utilisée traditionnellement pour attribuer une artčre unique pour de multiples utilisateurs est le multiplexage en fréquence : FDM (Frequency Division Multiplexage). Elle est aussi appelé AMRF (Accčs Multiple par Répartition de Fréquences). C’est ŕ dire que si il y a ‘n’ utilisateurs, la bande de fréquences disponibles sera découpée en ‘n’ canaux égaux, un pour chaque utilisateur.
Cette méthode est conseillée lorsqu’un nombre réduit fixe d’utilisateurs, ayant une forte charge de trafic.
Cependant, lorsque le nombre d’utilisateurs est important et varie fréquemment ou encore lorsque le trafic se déroule sous forme de rafales courtes et répétitives, alors le multiplexage FDM présente de gros inconvénients. Si sur les ‘n’ utilisateur possible, seulement une petite partie est active, alors toute la bande passante réservée aux utilisateurs non actifs sera inutilisable.
A l’inverse s’il y a un nombre équivalent ou supérieur ŕ ‘n+1’ alors un certain nombre d’utilisateur ne pourra pas communiquer du fait d’une pénurie de bande passante.
B. Les allocations dynamiques.
Il y a 5 points clés permettant d’aborder l’allocation dynamique de canaux de communication :
1. Modčle de Station.
Les stations sont indépendantes, leur activité est stable et constante. Les stations n’effectuent qu’une seule opérations ŕ la fois.
2. Présentation de canal unique.
Un seul canal logique de communication pour toutes les machines. Elles ont toutes le męme matériel de transmission, seul les logiciels peuvent introduire un mécanisme de priorité.
3. Présomption de collision.
Si deux trames sont émises en męme temps. Elles se télescopent, les signaux se mélangent et le résultat est donc inexploitable. Toutes les stations peuvent détecter les erreurs, toute erreur de transmission implique une réémission de cette trame.
4. Synchronisation temporelle.
+ La transmission sans réserve.
Les transmissions peuvent commencer ŕ n’importe quel moment, les stations n’étant pas coordonnées temporellement.
+ Le partage temporel.
Le temps est subdivisé en intervalle de temps appelé "Slots". La transmission commence toujours au début d’un "Slot". Cet intervalle de temps peut contenir 0,1 ou encore ‘n’ trames mélangées correspondant aux différents états :
- Disponibilité du canal
- Transmission réussi
- Collision entre 2 ou plusieurs trames
5. Anticipation d’erreurs.
+ Détection de porteuse.
Les stations peuvent, avant d’émettre, observer le canal de transmission par analyse de la porteuse (signal circulant dans le canal de transmission).
+ Pas d’écoute préalable.
Les stations émettent sans précaution particuličrement sur l’état du canal : elles déterminent plus tard si la transmission a réussie ou non.
3-Les protocoles de Gestion d’Accčs.
A. Les protocoles ALOHA.
Ils furent inventés, en 1970 par l’université d’Hawaii, pour résoudre les problčmes d’allocation de canal. Nous allons étudier 2 types de protocoles ALOHA.
Leurs différences résident dans leur mode de synchronisation temporelle des transmissions.
1. Le systčme ALOHA pur.
Il fonctionne sur le principe qu’il laisse les stations transmettre les trames en toute liberté. L’inconvénient majeur vient du fait qu’il peut se produire des collisions ŕ n’importe qu’elle moment.
En cas de destruction de trames. L’intervalle de temps avant la réémission est aléatoire pour éviter un cercle vicieux.
2. Le systčme ALOHA discrétisé.
Ce systčme permet de doubler la capacité de transmission du systčme ALOHA pur. Cette méthode introduit des intervalles de temps répétitifs ("Slots") de durée constante .
B. Les protocoles CSMA (Carrier Sense Multiple Access).
Dans un réseau LAN, une station peut s’enquérir de l’activité des autre stations et adapter ainsi son comportement. Ces réseaux permettent ainsi d’obtenir des performances améliorées.
Cette études de l’extérieur se base sur l’observation. Elle porte donc le nom de "Protocoles ŕ détection de porteuse" (Carrier Sense Protocols).
1. Le CSMA 1-persistant.
Lorsqu’une station veut émettre une trame, elle écoute d’abord l’activité sur le canal. Si le canal est occupé, elle maintient l’écoute et dčs que le canal se libčre, elle émet sa trame.
Il tire son nom du fait que lorsque la station décide d’émettre, la probabilité que le canal soit libre est égal ŕ 1.
2. Le CSMA non - persistant.
Il fonctionne de la męme maničre que le canal CSMA 1-persistant ŕ la différence que si le canal est occupé, il ne reste pas ŕ l’écoute mais il attend un intervalle de durée aléatoire avant de réémettre.
3. Le CSMA/CD (CSMA avec détection de collision. )
Ceci est une amélioration de CSMA car grâce ŕ cette version, la station émettrice cessera immédiatement ses transmissions si elle détecte un conflit avec une autre station. Cela permet ainsi de libérer de la bande passante et de gagner du temps.
La couche OSI n°3 :
La couche Reseau
1-Introduction.
- Offre une interface de service ŕ la couche Réseau (couche n°3).
- Détermine la façon dont les bits reçus par la couche physique sont agencés en trames.
- Traitement des erreurs de trames.
- Contrôle de flux pour réguler le volume des données échangées entre les hôtes.
2-Fonction Principale : Transmission de données de la couche Réseau d’un Hôte A ŕ celle d’un Hôte B.
La couche réseau de l’émetteur contient un processus qui délivre des bits ŕ la couche Liaison de données. Il appartient ensuite ŕ celle-ci de les transmettre au destinataire afin que sa couche réseau les traites.
Pour ętre en mesure de délivrer ce service ŕ la couche réseau, la couche Liaison de données doit utiliser les services de la couche physique afin d’effectuer le transport physique des données. Ce flux de donnée effectue un chemin imagé sur la figure 1. Néanmoins il est admis que le flux de données effectue un chemin virtuel ne citant pas la couche physique, les couches liaisons de données communiquant ainsi par l’intermédiaire d’un protocole de liaison.
Figure 1 – chemin de communication Réel et Virtuel
Les services fournies par cette couche varient selon les systčmes informatiques mais ils peuvent ętre classés parmi 3 catégories :
- fiable - Les services sans connexions et sans accusé de Réception.
- Les services sans connexions et avec accusé de Réception.
+ fiable - Les services avec connexions et avec accusé de Réception.
A :La notion de trames.
La couche liaison de données de l’émetteur reçoit des paquets de bits de sa couche réseau. Pour faciliter leurs envois, la couche liaison de données les partages en trames et en calcule une somme de contrôle d’erreur pour pouvoir detecter les erreurs de transmission (éronage de bits, de trames …).
Lorsqu’une trame est reçue, le récepteur recalcule immédiatement la somme de contrôle d’erreur. Si la somme n’est pas conforme ŕ la trames, la couche liaison du récepteur sait alors qu’il y a eut un problčme et elle prend alors les mesures en conséquences.
Les types de contrôle d’erreur sont :
- Le compteur de caractčre.
- Avec caractčre de début de trames, de fin de trames et de transparence.
- Avec utilisation de fanions de début, de fin de trames, avec des bits de transparence.
- Violer le codage normalement utilisé dans la couche physique.
B :Le contrôle d’erreur.
Généralement, les protocoles permettent ŕ l’émetteur de s’informer sur le fonctionnement du récepteur. Et ce par l’intermédiaire de trames de contrôle mais il peut y avoir des problčmes :
+
Pas de réception de trames.
- Pas d’émission de trames de contrôle de l’émetteur.
- Utilisation d’un temporisateur par le récepteur.
- réémission de la trame jusqu'ŕ réception.
+
Erreur détecté dans la tram reçue.
- Emission d’une trame de contrôle négative par le récepteur.
- réémission de cette trames.
+
Réception complčte ou partiel d’une trame.
- Emission d’une trame de contrôle.
- Pas de réception de la trame de contrôle.
- Temporisation de l’émetteur
- réémission de la trame (possibilité de doublons).
C’est ŕ la couche de liaison de résoudre les problčmes de doublons de trames.
C. Le contrôle de flux.
Il s’agit d’un mécanisme permettant de réguler le débit de bits partant d’un émetteur ŕ haut débit pour un récepteur moins rapide car męme si les bits sont envoyé sans erreur, le récepteur les perdra par un manque de rapidité de traitement.
Il se base sur un principe de rétroactions, c’est ŕ dire que l’émetteur ne peut envoyer des trames ou récepteur que si celui-ci lui en donne l’autorisation.
1-LA COUCHE RESEAUX DANS INTERNET.
Au niveau de la couche réseau, l’Internet peut-ętre considéré comme un vaste ensemble de sous- réseau entičrement autonome. Nous pouvons remarquer une hiérarchie dans cette infrastructure.
+ Les réseaux fédérateurs. (Epines Dorsale ou Bone Black)
Ils sont constitués par de grosses artčres (Bone) de communication ainsi que des routeurs ultra rapides (ex : ligne Transocéanique)
+ Les réseaux Régionaux (Plaques régionales.)
Ils sont constitués de grands opérateurs nationaux comme France Télécom (Numéris, RTC, Transpac) ainsi que de réseaux spécialisés comme le réseau universitaire et scientifique (Le réseau RENATER).
+ Les réseaux Locaux.
Ils sont constitués, dans la plupart des cas, de réseaux de type LAN. Tous ces réseaux hétérogčnes peuvent coopérer grâce ŕ un protocole : Le protocole IP (Internet Protocole). Le protocole a pour vocation l'inter-résautage (internetworking).
Les communications se déroulent de la maničre suivante :
í
La couche "Transport" reçoit un flux de données provenant d’un processus applicatif et le partage en morceaux appelés "Datagrammes IP". Les Datagrammes IP peuvent ętre fragmentés en plus petits morceaux : "Les fragments IP".í
Le Datagrammes est transféré au récepteur par le biais du réseau Internet.í
A la réception du flux de données, la couche réseaux de l’hôte destinataire réordonne les paquets pour reconstituer le Datagramme d’origine.í
Ce Datagramme est alors passé ŕ la couche Transport pour qu’elle reconstitue le flux de données d’origine afin d'ętre utilisé par les processus applicatifs
2-LE PROTOCOLE IP
A. Introduction :
Il réalise les fonctionnalités de la couche réseau selon le modčle
OSI. Se situe au cœur de l’architecture TCP/IP qui met en œuvre un mode de
transport fiable (TCP) sur un réseau en mode non connecté. Le service offert par le
protocole IP est dit non fiable (pas de réponse de la machine receveuse ) c'est-ŕ-dire
que la remise des paquets est non garantie.
Il n’y a pas de connexion ente les datagrammes (chaque paquets est traité
indépendamment les uns des autres) et la diffusion d’un message est faite pour le
mieux.
Le protocole IP définit :
í
L’unité de donnée transférée dans les interconnexions (datagramme).í
La fonction de routage.í
Les rčgles qui mettent en œuvre la remise de paquets en mode non connecté.B. Composition d’un datagramme :
Un Datagramme IP est composé de 2 champs d’information :
í un champ en-tęte
í un champ donnée (constitue la charge utile du Datagramme)
32 Bits
1 |
8 |
16 |
24 |
32 |
|||||||||||||||||||||||||||||
Version |
Long. |
Type de service |
Longueur Totale |
||||||||||||||||||||||||||||||
Identification |
Flags |
Offset Fragment |
|||||||||||||||||||||||||||||||
Durée de vie |
Protocole |
Somme de contrôle en-tęte |
|||||||||||||||||||||||||||||||
Adresse IP source |
|||||||||||||||||||||||||||||||||
Adresse IP destination |
|||||||||||||||||||||||||||||||||
Options IP (C | classe d’option | numéro d’option) |
Padding |
||||||||||||||||||||||||||||||||
Champs de données |
|||||||||||||||||||||||||||||||||
Figure 1 – composition d’un datagramme IP.
NB : Le champ d’options est le seul qu’il est necessaire d’expliciter. Il est facultatif et de longueur variable.
Une option est définie par un champ octet composé de 3 parties : C, Classe d’options et Numéro d’option :
- Copie (C) indique que l’option doit ętre recopiée dans tous les fragments (C=1) ou bien uniquement dans le premier fragment (C=0).
- Les bits classe d’option et numéro d’option indiquent le type de l’option et une option particuličre de ce type :
- Enregistrement de route : est utilisé pour enregistrer l’itinéraire. Chaque routeur donne son adresse au datagramme
- Routage strict prédéfini par l’émetteur : prédéfini le routage qui doit ętre utilisé dans l’interconnexion en indiquant la suite des adresses IP dans l’option. Le chemin spécifié ne tolčre aucun autre intermédiaire. Le routage lâche permet le transit par d’autre intermédiaire
- Horodatage : chaque routeur joint son adresse et en plus une horodate (date universelle )
Chaque ordinateur ou routeur possčde une adresse IP qui lui est
propre.
Cette adresse peut ętre définit selon 2 méthodes différentes :
í Technique d’allocation dynamique lors de l’ouverture de la connexion.
í Technique d’allocation statique.
Des ordinateurs connectés simultanément sur plusieurs réseaux possčdent une adresse IP par réseau.
Seul le NCI (Network Information Center) peut attribuer des adresses de réseaux..
C. Format d'une adresse IP :
Une adresse IP est un nombre codé sur 4 octets. Par habitude, cette adresse est représentée sous la forme décimale pointée w.x.y.z oů w,x,y,z sont quatre chiffres décimaux allant de 0 ŕ 255.
Une adresse IP est, elle-męme, composé de :
í Un identifiant réseau.
í Un identifiant ordinateur.
Néanmoins, certaines adresses sont absentes des plages IP car elles sont réservées :
Tableau 1 – Adresses IP particuličres.
Tout ŕ zéro |
" Cet " ordinateur Ŕ |
|||
Tout ŕ zéro |
Id_ord |
Un ordinateur sur " ce " réseau Ŕ |
||
Tout ŕ 1 |
Diffusion limitée au réseau d’attachement. Á |
|||
Id_res |
Tout ŕ 1 |
Diffusion dirigée vers " ce " réseau. Á |
||
127 |
Nombre quelconque |
Adresse de rebouclage . Â |
||
Ŕ Autorisée uniquement au démarrage de l’ordinateur, ne constitue jamais une adresse valide.
Á Ne constitue jamais une adresse valide.
 Ne doit jamais apparaître sur un réseau.
D. Les différentes classes d'adresses.
Les adresses IP peuvent ętre rassemblées selon 3 types différents :
í Adresses de classe A (épines dorsale).
Elle alloue 7 bits pour l’ID-res et 24 bits pour l’id-ord.
Elles définissent jusqu'ŕ 126 réseaux composés de 16 millions d’ordinateurs.
í Adresses de classe B (Réseaux intermédiaires).
Elle alloue 14 bits pour l'ID-res et 16 bits pour l’id-ord. Cette classe d’adresse permet l’adressage de 28 ŕ 216 ordinateurs.
Elles définissent jusqu'ŕ 126 réseaux composés chacun de 65536 ordinateurs.
í Adresses de classe C (Réseaux locaux).
Elle alloue 21 bits pour l’ID-res et 8 bits pour l’id-ord.
Elles définissent jusqu'ŕ 2 millions de réseaux composés chacun de 254 ordinateurs.
Il existe 2 classes supplémentaires peu ou pas utilisée:
í Adresses de classe D.
Elles sont utilisées pour l’émission de datagrammes ‘multidestinataires’, c’est ŕ dire ŕ un groupes d’ordinateurs.
í Adresses de classe E.
Cette classe d’adresse a été prévue et réservée en vue d’une utilisation ultérieur.
Classes d’adresse |
Adresses les + basses |
Adresses les + hautes |
A |
0.1.0.0 |
126.0.0.0 |
B |
128.0.0.0 |
191.255.0.0 |
C |
192.0.1.0 |
223.255.255.0 |
D |
224.0.0.0 |
239.255.255.255 |
E |
240.0.0.0 |
247.255.255.255 |
Tableau 2 – Tableau de répartition des adresses IP par classes.
3-LES PROTOCOLES DE CONTROLES D’INTERNET
En complément du protocole de transfert IP, Internet utilise des protocoles de gestion et de contrôle dans la couche réseau :
í Le protocole ARP (Adress Resolution Protocol) :
L’acheminement des Datagramme n’utilise pas directement l’adressage IP, car ceux-ci sont transférés ŕ la couche liaisons qui utilisent des adresses propres pour envoyer des trames.
De ce fait, il est affecté ŕ toute cartes réseaux (ex : carte Ethernet) une adresse de 48 bits lors de sa fabrication. Les constructeurs de cartes, hub … obtiennent ces adresses auprčs de l’autorité de l’IEEE. Elles sont insérées en "en dur" sur chaque carte tout en sachant qu’il ne doit pas y avoir de redondance d’adresse.
Le protocole ARP permet donc de déterminé l’adresse "Hardware" d'aprčs l'adresse IP d'un hôte.
í Le protocole RARP (Reversed Adress Resolution Protocol)
A l’inverse du protocole ARP, le protocole RARP permet ŕ la couche réseau de connaître une adresse IP d'aprčs l’adresse "Hardware". Ce qui est particuličrement utile, par exemple, pour démarrer une machine sans Disque Dur.
í Le protocole ICMP (Internet Control Message Protocol)
Lorsqu’un événement inattendu intervient au niveau interne (c'est ŕ dire au niveau des routeurs). Ce protocole rapporte ainsi ce problčme par le biais de code d’erreurs.
4-L’EVOLUTION DU PROTOCOLE IP : L’Ipv6
Tandis que la technique permet de repousser les limites d’adresse IP sous leur forme actuelle : L’IPv4. Le nombre d’utilisateur du réseau Internet connaît une croissance exponentielle depuis les années 1990.
En effet, le réseau des réseaux n’a plus seulement pour visiteurs et usagers des universitaires, ingénieurs et administration militaires… car de plus en plus des particuliers et des entreprises s’intéresse ŕ ce qui se passe au sein de cette toile.
Voyant ce problčme pointer au début des années 90, l’IETF débuta ses travaux sur un solution de remplacement de la version actuelle de l’IP (IPv4).
Cette solution a pour but :
í De palier ŕ ce manque d’adresse de maničre définitive.
í De résoudre toute une variété de nouveaux problčmes.
í D'offrir plus de flexibilité et de fiabilité.
Ses objectifs sont :
í Fournir des milliards d’adresses.
í Réduire les tables de routage.
í Simplifier le protocole pour une transmission plus rapide des Datagramme.
í Permettre une meilleure sécurité (authentification et confidentialité)
í Accroître l’attention sur le type de services offerts
í Etc.
Seul point noir dans ce nouveau protocole, l’IPv6 n’est pas compatible avec l’IPv4 mais il reste tout de męme compatible avec les autres protocoles : TCP, UDP, ICMP, IGMP, OSPF, BGR, DNS, …
LES NOUVEAUTES DU PROTOCOLE IPv6.
Il utilise des adresses codées sur 16 octets, au lieu de 4 octets pour l’ancienne version (soit 128 bits contre 32 bits). Ce qui permet ŕ l'Ipv6 de fournir un nombre quasi-illimité d’adresses.
Les adresses Ipv6 sont composées de 8 groupes de 4 nombres hexadécimaux séparés par 2 points.
Ex : 0016 : 0000 : 72A1 : 3295 : B190 : 32EA : A0BF : 1600.
Pour simplifier la notation, les zéros peuvent ętres retirés.
Ex : 16 :: 72a1 : 3295 : B19 : 32EA : A0BF : 16
Cette version fournit environ 2128 adresses, soit environ 3 x 1038. Donc, si la terre entičre (terre + eau) était recouverte d’ordinateurs, le protocole IPv6 pourrait fournir 7 x 1023 adresses par m2, soit autant d'ordinateurs, de routeurs, de HUB …
Le protocole IPv6 opčre une simplification de l’entęte de Datagramme. Ceci permet donc :
í
l'accélération des traitements lors de routages, ce qui permet d'acheminer plus rapidement les Datagrammes.
í plus de souplesse dans les options.
í
l'accélération du chargement des Datagramme
í l'amélioration de la sécurité de façon majeur (authentification et confidentialité).
La couche OSI n°4 :
La couche Transport
1-Introduction.
La couche Transport est défini dans le but de fournir un service de transfert de données de haute fiabilité entre deux ordinateurs "maîtres" raccordés sur un réseau de type "paquets commutés", et sur tout systčme résultant de l'interconnexion de ce type de réseaux.
Pour cela elle utilise les services que lui fournit la couche Réseau, qui est alors appelé ‘Entité Transport’.
Elle peut ętre situé dans plusieurs endroits :
í dans le noyau du Systčme d’exploitation.
í dans un processus utilisateur.
í dans une machine ŕ interface spéciale.
2-Les Services fournit par la couche Transport.
La couche Transport fournit 2 types de services :
í Le service avec connexions.
Ils ressemble service Réseau point ŕ point et utilise 3 phases successives :
- Etablissement de la connexion.
- Transfert de données.
- Libération de la connexion.
í Le service sans connexions.
De męme que le service avec connexion, le service sans connexion ressemble aux services réseau sans connexions.
Un service de Transport est composé de primitives, ceux-ci permettant ŕ l’utilisateur d’y accéder. Chaques services de Transport possčde ses propres primitives.
Les paquets émis par l’intermédiaire d’une entité de transport sont appelé TPDU (Transport Protocol Data Unit).
L’existence d’une couche de transport permet d’avoir des transmissions beaucoup plus fiable qu’avec le service réseau sous-jacent. Les paquets perdus peuvent ętre détecte et compensé par la couche Transport.
Une autre maničre de définir la couche Transport est d’étudier son rôle de garant de la ‘Qualité de Transport’. Celle ci permettant de combler le fossé entre la demande de l’utilisateur et la qualité des services offerts par la couche Réseau.
3-La Couche Transport dans l’Internet.
La couche Transport d’Internet dispose de 2 protocoles de Transport :
í Le TCP (Transfer Control Protocol).
í L’UDP (User Datagram Protocol).
A. Le protocole TCP.
TCP est un protocole de transport de la famille TCP/IP. On dit que TCP est un protocole de bout en bout (END to END). Lorsque deux applicatifs utilisent TCP pour échanger des données, l'émetteur est sur que le récepteur reçoit exactement les données qui sont émises.
TCP gčre les contrôles, ce sont les logiciels TCP qui redemande la transmission de paquets lorsque ces derniers ne sont pas arrivés sur le destinataire.
Il assure également la remise dans l'ordre des paquets échangés.
Si TCP s'appuie sur IP, il tente d'en corriger les défauts.
Pour avoir un service TCP, il faut créer 2 points de connexions appelés ‘sockets’ (l’un coté émetteur, l’autre coté recepteur). Chaques Sockets possčde une adresse composé de l’adresse IP du poste Hôte et un nombre de 16 bits local ŕ cette hôte qui est appelé un ‘Port’. Pour un service TCP, il faut établir une connexion explicite entre 2 sockets.
Les ports inférieurs ŕ 256 sont des " ports réservés " qui sont utilisés par les services les + courants.
Par ex : Le port 21 ŕ contact un client FTP.
Le port 23 ŕ etablir une session ŕ distance via Telnet.
Toutes connexions est bidirectionnelle et en mode Point ŕ Point.
B. Le protocole UDP.
UDP est un protocole de transport qui est trčs proche d'IP. UDP permet d'échanger des informations (USER DATAGRAMM) entre des applications.
UDP prend le datagramme de l'utilisateur et le transmet ŕ la couche IP. Cette derničre l'achemine sur la machine destinataire pour le remettre au protocole UDP.
Ce dernier redonne le datagramme au processus distant. Comme UDP se contente de donner le datagramme ŕ IP et ne fait aucun contrôle, il n'est pas sur que le datagramme arrive ŕ destination, et que s'il y arrive, il n'est pas sur qu'il soit intact. Il peut avoir été fragmenté par les passerelles, les fragments ne seront pas réassemblés par UDP sur la machine du destinataire.
Il est possibles que des fragments n'arrivent jamais, ou qu'ils arrivent dans le désordre. C'est aux applicatifs utilisant UDP de faire tous ces contrôles.
UDP est trčs peu sécurisé, il a été écrit et normaliser car il est trčs simple ŕ mettre en œuvre.
Sa simplicité permet de l'utiliser pour télécharger des OS sur des machines. UDP ouvre et referme une connexion pour chaque datagramme.